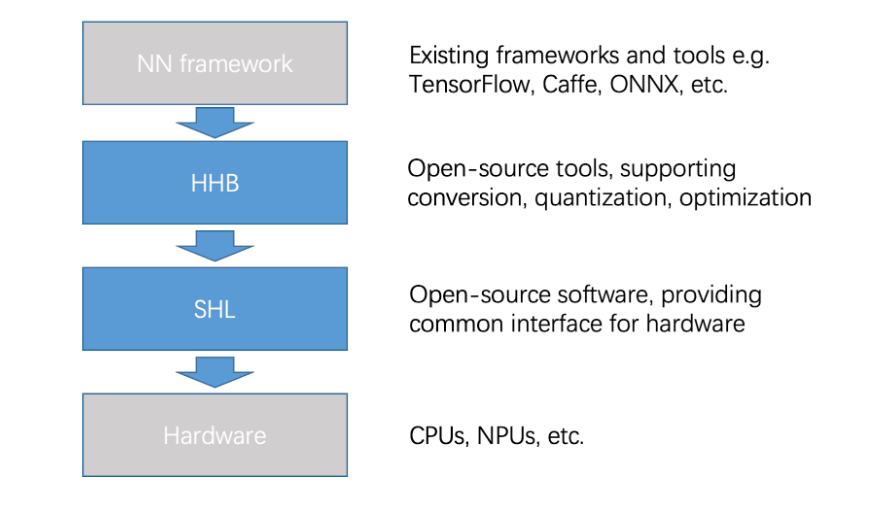
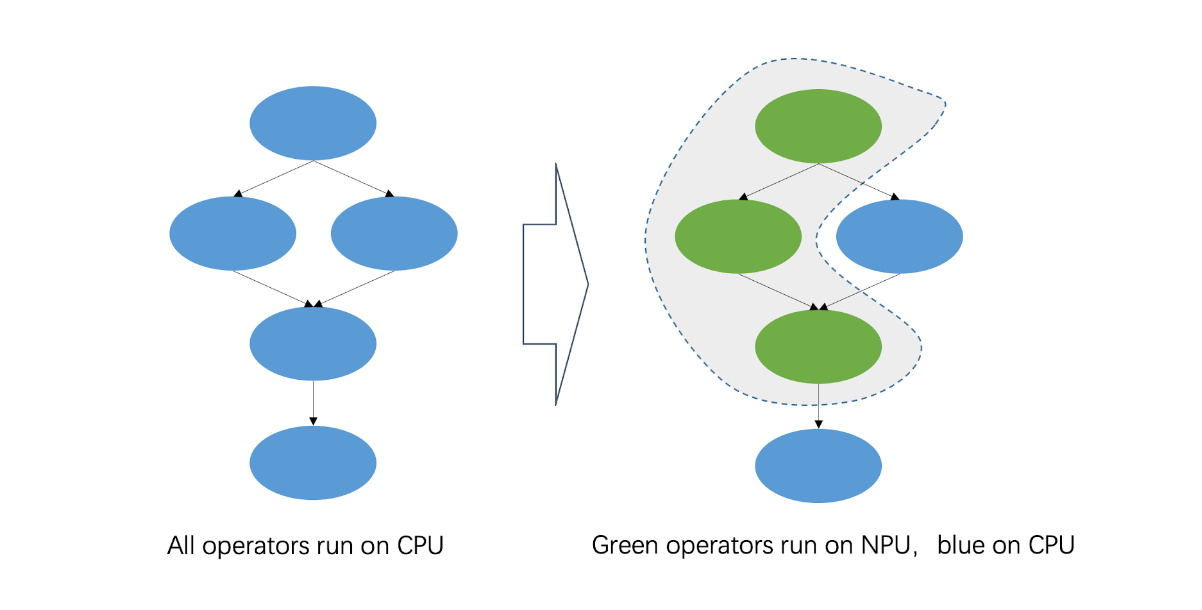
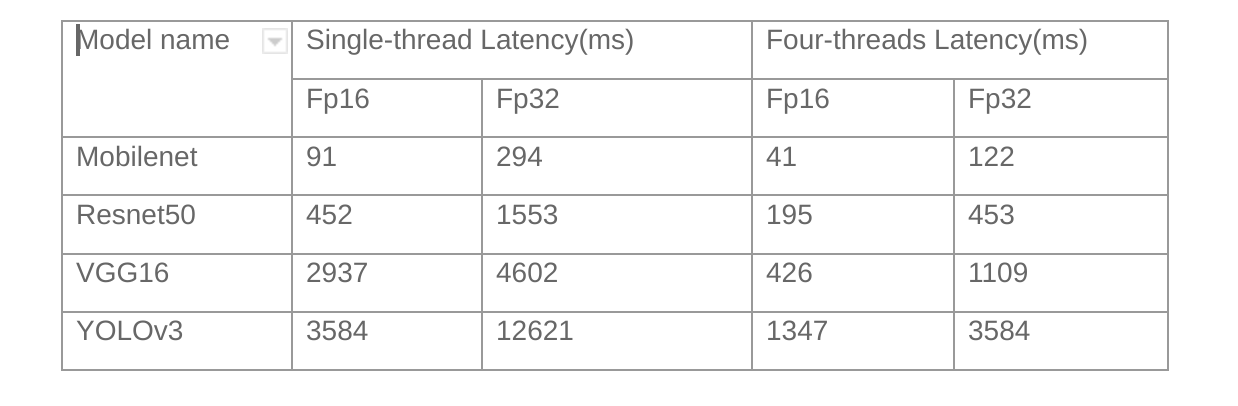
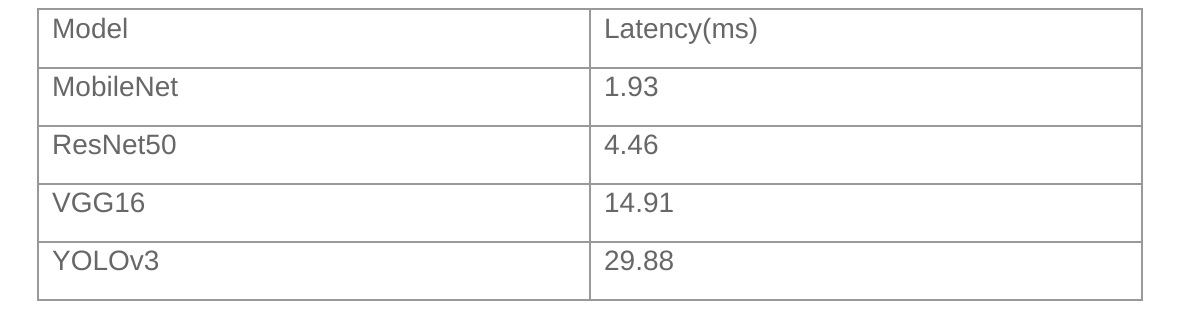
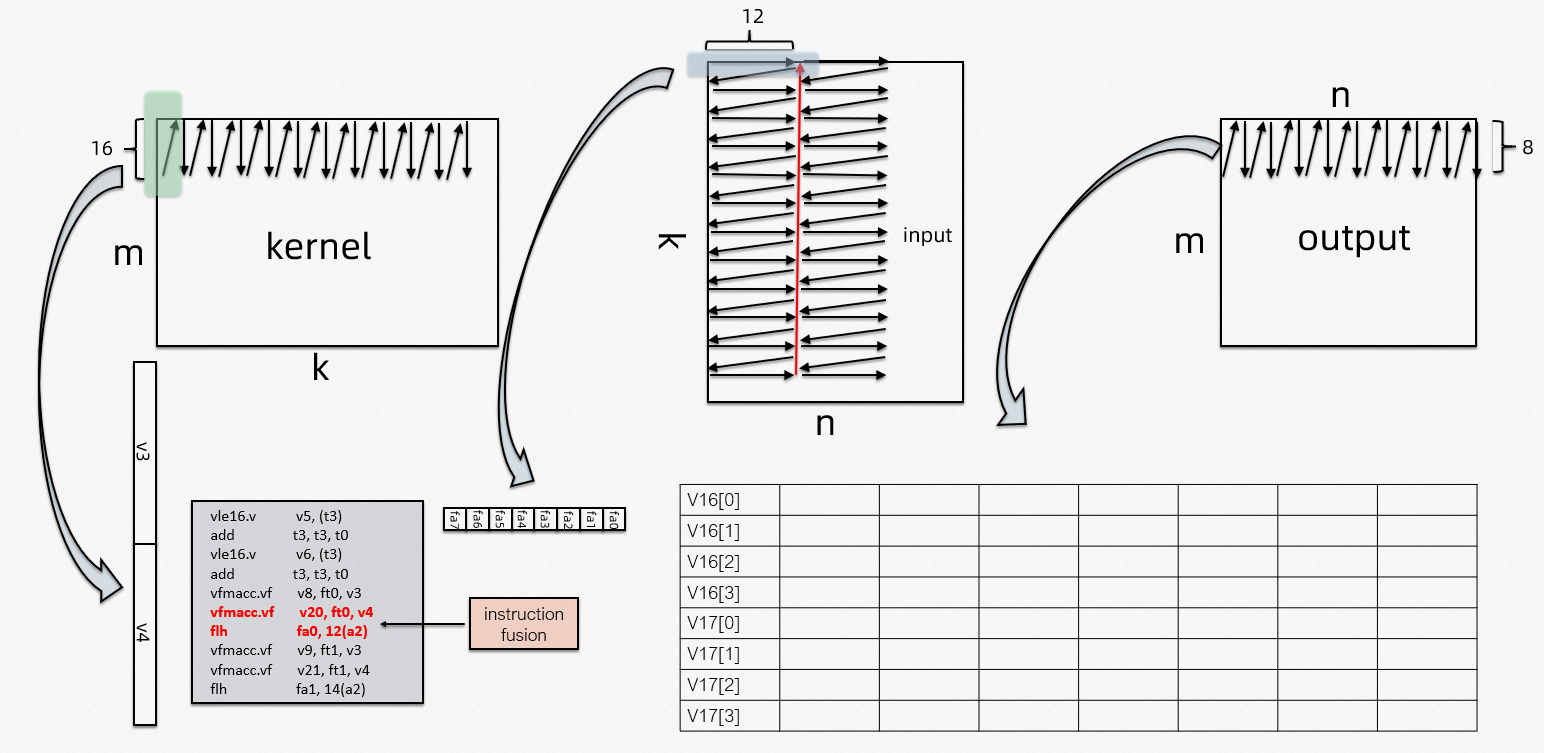
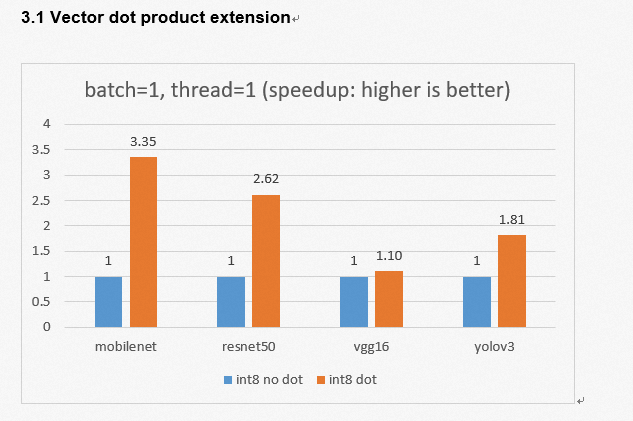
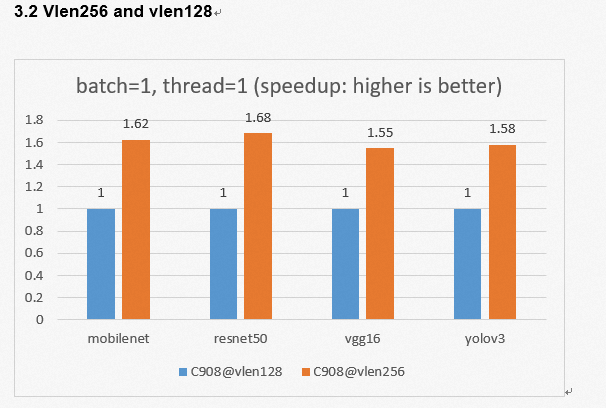
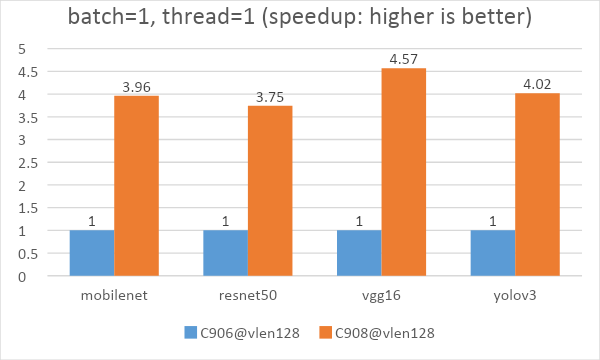
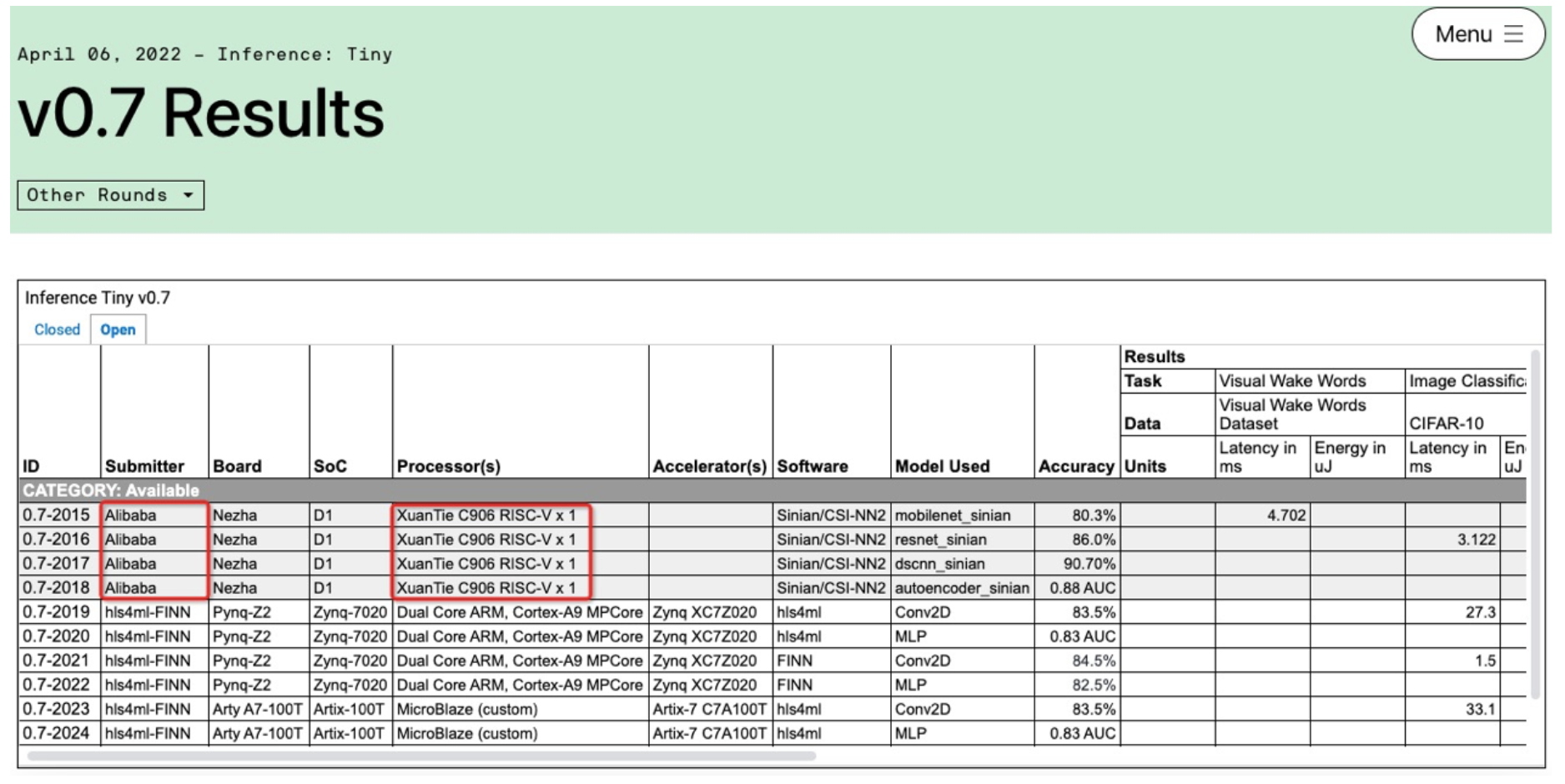
In order to enhance the AI inference ability of the Xuantie processor, T-Head propose a matrix extension Instruction set. The following is an example of AI inference introduced through the T-Head open source AI deployment package.
1 docker
Pull the image hhb:2.1-matrix that supports matrix extension from docker hub, start a container, and open a terminal in interactive mode in the container:
docker pull hhb4tools/hhb:2.1-matrix
docker run -itd --name=your.hhb2.1-matrix -p 22 -v /your_mount_dir/:/mnt "hhb4tools/hhb:2.1-matrix"
docker exec -it your.hhb2.1-matrix /bin/bash
After entering container, you can use the hhb --version command to confirm:
root@c14249f8243c:/# hhb --version
HHB version: 2.1.x-matrix, build 20230131
docker installation guide:Docker Engine installation overview
2 Model deployment
Take the deployment of MobileNet as an example, in /home/rvm_caffe_mv1_int8, there is already a complete Makefile script, execute the make command to convert the model into the required sample program, which can be executed on RISC-V architecture chips that support matrix extension.
cd /home/rvm_caffe_mv1_int8
make
The key steps in the model deployment process are described below:
2.1 Model compilation
HHB is an offline AI model compilation and optimization tool. Executing the following commands can quantize the original model, optimize operators such as operator fusion, and generate a C code model with high execution efficiency on the target chip.
hhb -C --calibrate-dataset ./cat.jpg --model-file ./mobilenetv1.prototxt ./mobilenetv1.caffemodel --data-scale 0.017 --data-mean '104 117 124' --output . --board rvm --quantization-scheme="int8_asym_w_sym" --pixel-format BGR --fuse-conv-relu --channel-quantization --target-layout NHWC
The model compilation options are described as:
- -C :specifies to execute the main command until C code is generated.
- --calibrate-dataset:specifies the calibration image used for quantization.
- --model-file :specifies a MobileNet model downloaded to the current directory. A Caffe model is divided into two files. The files following the option are not sequence-sensitive.
- --data-mean :specifies a mean.
- --data-scale :specifies a scale.
- --output :specifies the current directory as the path to store files that you need to generate.
- --board :specifies the platform as the destination platform.
- --quantization-scheme :specifies a quantization scheme.
- --pixel-format:specifies the input image format required by the model, the default is RGB, and the BGR image needs to be set to BGR when the model is trained.
- --fuse-conv-relu:specifies relu fuse to convolution layer.
- -channel-quantization:specifies weight channel quantization.
- --target-layout NHWC:specifies the tensor layout.
After the command is executed, multiple files such as main.c and model.c will be generated in the current directory:
- data.0.tensor: cat.png preprocessed tensor by decoding.
- data.0.bin:data.0.tensor binary data.
- main.c:the reference entry to the sample program.
- model.c:a model structure file that describes the model structure.
- hhb.bm:HHB format model file.
- model.params:the weights converted to int8.
- io.c:the helper function for reading and writing files.
- io.h:the declaration of the helper function for reading and writing files.
- process.c:the image preprocessing function.
- process.h:the declaration of the image preprocessing function.
2.2 SHL library
SHL is a set of neural network library API for Xuantie CPU platform, and provides a series of optimized binary libraries. SHL supports convolutional layer-focused optimization by matrix extension, . In this example, the prebuilt inference library has been placed in the /home/install_nn2 directory, and the source code can also be downloaded and rebuild by the following steps.
git clone -b matrix https://github.com/T-head-Semi/csi-nn2.git
cd csi-nn2
make nn2_rvm
make install
2.2 Executable program
After hhb completes the code generation, execute the following compilation command to link the rvm high-performance library and generate the c_runtime program in the current directory:
riscv64-unknown-linux-gnu-gcc -O2 -g3 -march=rv64gcv_zfh_xtheadc -mabi=lp64d -I/home -I/home/install_nn2/include -I/home/decode/install/include -o c_runtime main.c model.c io.c process.c -L/home/install_nn2/lib -L/home/decode/install/lib/rv -ljpeg -lpng -lz -lstdc++ -lshl_rvm -lm -static -Wl,--gc-sections
The compilation option is described as follows:
- -O2 -g3: specifies the optimization option and debug-level.
- -march: specifies the architecture option for RISC-V matrix extension chip.
- -mabi: specifies the application binary interface (ABI) option for RISC-V matrix extension chip.
- -I: specifies the location of the header file that needs to be used during compilation.
- main.c model.c io.c process.c: the source file that you need to use for compilation.
- -L: specifies the path to store the specified library.
- -ljpeg: links to a JPEG decoding library.
- -lpng: links to a PNG decoding library.
- -lz: links to a zlib.
- -lstdc++: links to a standard C++ library.
- -lshl_rvm: links to an optimized version library of rvm in SHL.
- -lm: links to a standard math library.
- -static: a static link.
- -Wl,--gc-sections: recycles unused sections during linking.
The gcc version used in this example is V2.6.1, you can use the following command to check:
riscv64-unknown-linux-gnu-gcc -v
3 Simulate
After the compilation is complete, use T-Head's qemu simulation program to execute, and you can see the top5 execution results on the terminal:
qemu-riscv64 -cpu rv64,x-v=true,vext_spec=v1.0,vlen=128,x-matrix=on,mlen=128 c_runtime model.params data.0.bin
 The qemu version used in this example is V6.0.94, you can use the following command to check:
The qemu version used in this example is V6.0.94, you can use the following command to check:
qemu-riscv64 -version
4 Other
RISC-V matrix extension also supports fp16 data type, just modify the hhb compilation command as follows, and keep other steps unchanged, you can use fp16 for inference.
hhb -C --calibrate-dataset ./cat.jpg --model-file ./mobilenetv1.prototxt ./mobilenetv1.caffemodel
--data-scale 0.017 --data-mean '104 117 124' --output . --board rvm --quantization-scheme="float16"
--pixel-format BGR --target-layout NHWC